A Primer on Memory Consistency and Cache Coherence
- 书籍信息
- 我为什么读这本书?
- 学习memory order
- 阅读前问题
- 阅读中问题
- 阅读时的思考
- 主要内容
- 本文提到的其他书籍
- 评价
- 优点
- 缺点
Chap1 Introduction to Consistency and Coherence
Consistency的定义提供了load和store的规则以及它们如何作用于内存。
Coherence至于于让共享内存系统的Cache像单核系统上的Cache一样透明,使用将一个处理器的写入广播到其他处理器的方式。Consistency属于定义共享内存正确性的架构规范,而coherence是支撑consistency模型的一种方式。
对于特定输入的多线程程序,内存模型规定了dynamic load可以返回的值,可选的规定了内存最终的可能状态。通常允许多线程程序有多个正确的行为。
- Sequential Consistency(SC)中,多线程程序看起来像其中每个线程的交替执行,就像所有线程在单核机器上分时复用一样。
- Total Store Order(TSO),在将结果写入Cache前,使用FIFO的write buffer来保存committed store的结果。相比SC有更好的性能。
- Relaxed or Weak Model,动机在于大部分强模型中的内存顺序是不必要的。例如,修改10个数据项和1个同步标记,10个数据项具体的内存顺序是不重要的,只需要保证在同步标记之前修改即可。
在多核同时访问数据的多个副本,且至少有一个访问是写操作时会有coherence问题。使用coherence协议来避免访问到过期数据。通过广播操作使得一个处理器的写操作对其他处理器的Cache可见。目前基本是同步广播,异步广播机制正在出现。
- Database Replication. Synthesis Lectures on Data Management
- Quorum Systems: With Applications to Storage and Consensus. Synthesis Lectures on Distributed Computing Theory
Chap2 Coherence 基础
在多种角色访问Cache和Memory时有coherence问题,如处理器、DMA、其他设备。
-
Consistency-agnostic coherence。使用同步写,写操作在返回前对所有核可见,提供的接口和(不带Cache的)atomic memory system相同。
- single-writer-multiple-reader(SWMR)不变式。
- 另一种方式,使用token对SWMR不变式来解释。token个数和核数相等,拿到所有token时,可以执行写操作;拿到一个或多个token时,可以执行读操作。
- 还要求给定内存的值被正确的广播,即数据值不变式:某个epoch开始时的值,等于上一个read-write epoch结束时的值。
Coherence invariants
- Single-Writer, Multiple-Read (SWMR) Invariant. For any memory location A, at any given time, there exists only a single core that may write to A (and can also read it) or some number of cores that may only read A.
- Data-Value Invariant. The value of the memory location at the start of an epoch is the same as the value of the memory location at the end of the its last read-write epoch.
- single-writer-multiple-reader(SWMR)不变式。
-
Consistency-directed coherence。写操作异步广播,coherence协议保证写操作以consistency模型强制的顺序最终可见,用以支持GP-GPU。
Coherence的单位为cache block(例如cache line)。
Chap3 Memory Consistency Motivation and Sequential Consistency
Reorder的类型
- Store-store reordering。如果核有非FIFO的write buffer可能会出现store-store reordering,第一个store miss而第二个store命中cache,或者第二个store可以和更早的store合并。
- Load-load reordering。
- Load-store和store-load reordering。
- store-load reordering可能由于本地跳过了FIFO的write buffer。
| Core C1 | Core C2 | Comments |
|---|---|---|
| S1: x = NEW; | S2: y = NEW; | /* Initially, x = 0 & y = 0 */ |
| L1: r1 = y; | L2: r2 = x; |
大多数实际的硬件,包括x86,允许r1=0, r2=0作为最终的结果,因为它使用了FIFO的write buffer来提高性能。
memory model是共享内存使用共享内存执行的多线程程序允许的行为的规范。
- Cache coherence does not equal memory consistency.
- A memory consistency implementation can use cache coherence as a useful “black box.”
Sequential Consistency(SC)
SC最早由Lamport形式化,单核上的SC和Program Order相同,多核上的SC,如果所有核上的操作以某种顺序执行,序列中每个核的操作和Program Order相同。SC中,memory order遵循每个核上的Program Order,而其他的consistency model允许不遵守Program Order的memory order。
定义<m为memory order, <p为program order。在SC中,memory order遵守program order,即op1 <p op2意味着op1 <m op2。
3.5 SC的的规范化定义
L(a)和S(a)为对内存地址a的load和store操作。<p为每个核上的total order,<m为global memory order。
- 所有的核将它们的load和store插入到<m中,遵守其program order,无论是否是相同的地址。四种情况:
- If L(a) <p L(b) ⇒ L(a) <m L(b) /* Load → Load */
- If L(a) <p S(b) ⇒ L(a) <m S(b) /* Load → Store */
- If S(a) <p S(b) ⇒ S(a) <m S(b) /* Store → Store */
- If S(a) <p L(b) ⇒ S(a) <m L(b) /* Store → Load */
- 每一个load得到的值为依global memory order在该load之前写入的值。
对于原子的read-modify-write操作(如test-and-set),要求load和store操作连续,中间不能有其他的内存操作(无论是相同还是不同的地址)。
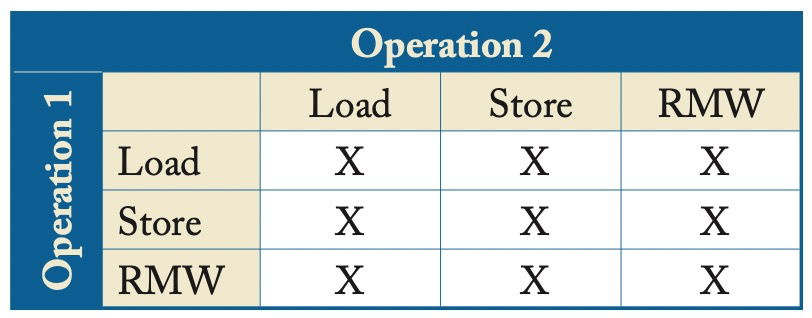
表中定义了SC允许的行为,其中Operation 1在Operation 2之前,X意味着必须遵守program order。
一个SC实现只允许SC执行,这是safety属性(do no harm),SC实现还有liveness属性(do some good)。
3.6 SC的naive实现
-
使用单核来执行多线程程序, 在线程切换之前所有pending的内存操作必须完成。
-
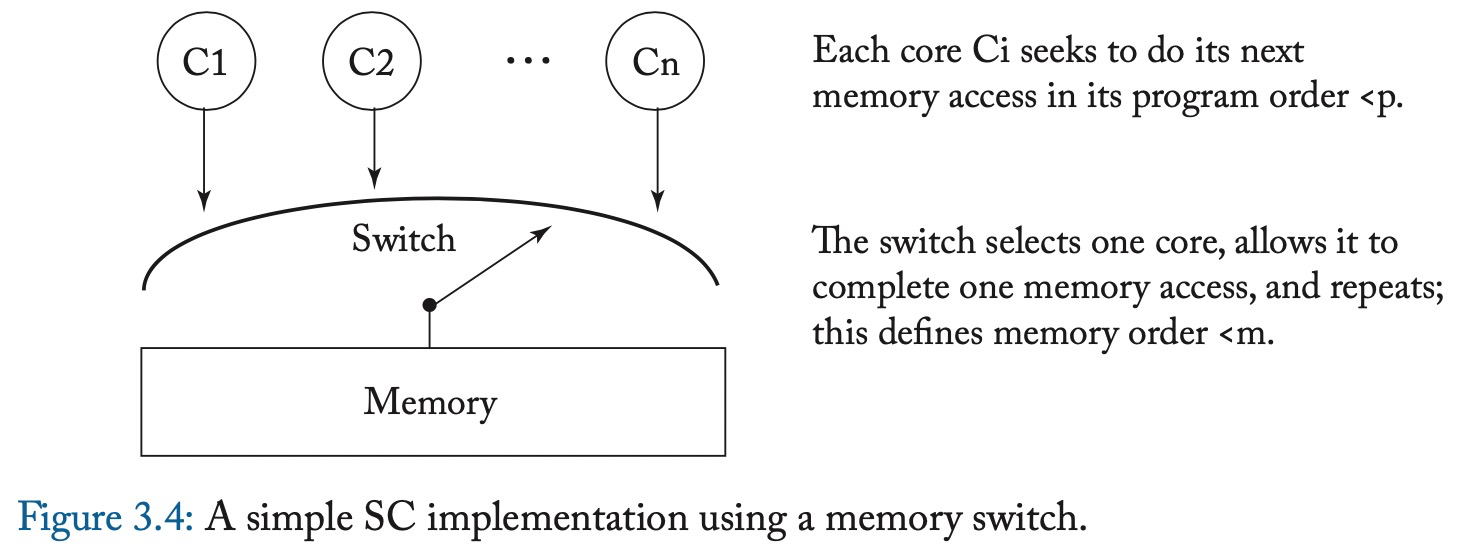
使用一组核、内存和内存开关来实现,开关选取一个核来满足其内存访问请求,这定义了memory order <m。
- 该实现中不需要cache或者coherence。
3.7 带有cache coherence的基本实现,能够并行的执行不冲突的load和store操作
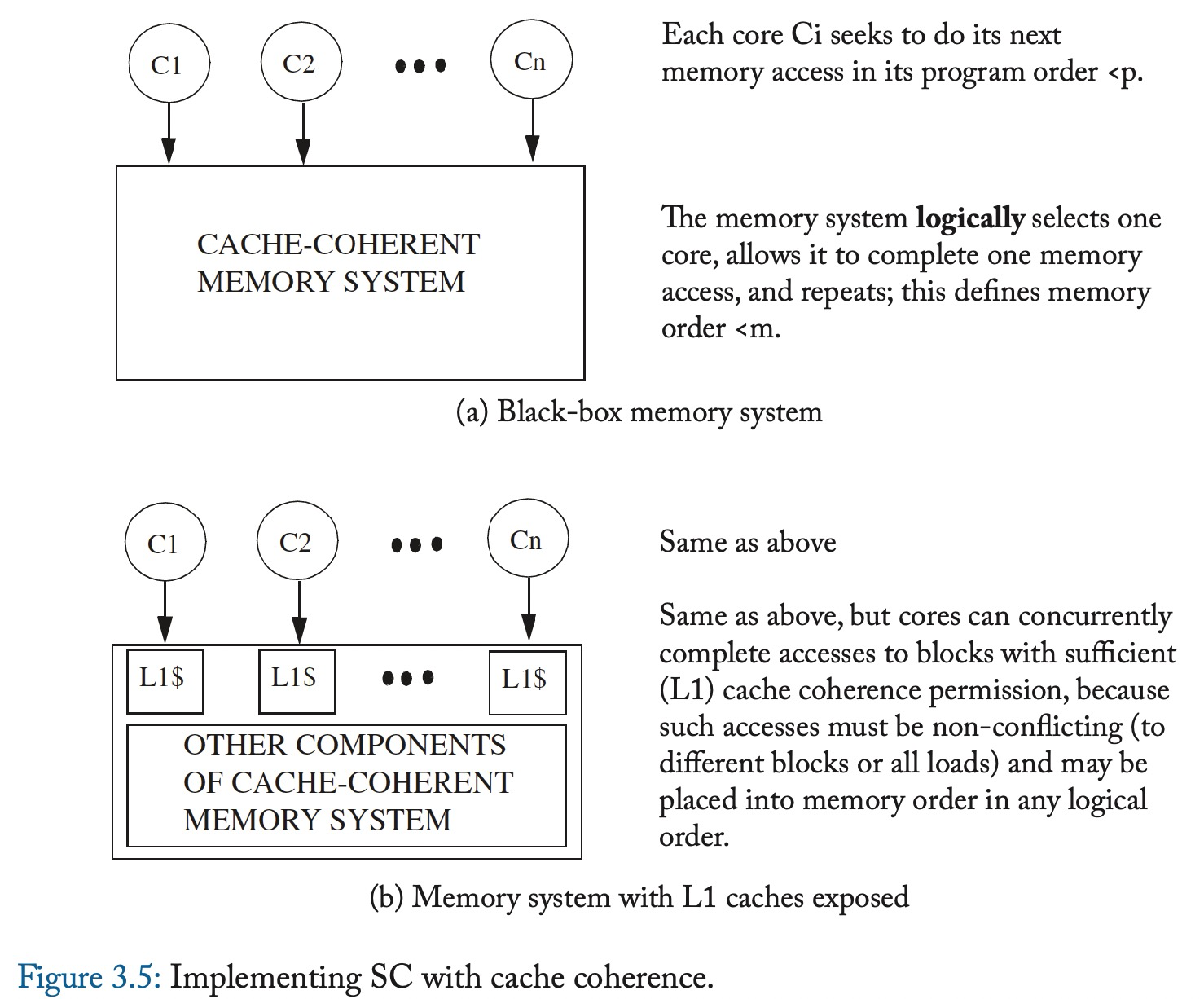
这个SC实现中
- 充分利用了cache的时延和带宽优势。
- 和它使用的cache coherence协议有相同的扩展性。
- 将实现core从实现coherence的复杂度解耦开。
3.8 继续优化
-
Non-Binding Prefetching。对块B的非绑定预取是指向coherent内存系统发请求来改变一个或多个cache中的coherence状态。重要的是,非绑定预取不会修改寄存器的状态或者块B中的数据,对memory consistency model相当于no-op。
-
Speculative Cores。推测执行在分支预测失败时,会无效化之前的操作,称为squashing,squashed的load和store操作看起来像非绑定预取,不影响SC。对store,可能会提前发起GetM预取,但只有store保证提交时才写入cache。
-
Dynamically Scheduled Cores。乱序执行,如将L2提到L1之前执行,有两种方式来检查预测的正确性。
- 在核推测执行完L2,但在提交前,检查是否脱离了cache,监听L2相关的内存地址是否有GetM请求。
- 在核准备提交load前,重放推测的load,检查结果是否相同。
-
Non-Binding Prefetching in Dynamically Scheduled Cores。非绑定预取不影响SC。
- SC规定了load和store(看起来)应用到coherent memory的顺序,但没有规定coherent activity的顺序。
-
Multithreading。一个挑战是保证store在对其他核上的线程可见之前,相同核上的T1线程不能读到T2线程写入的值。
3.9 SC下的原子操作
原子的atomic-read-write操作可以如下优化:一个核以M状态获取到cache,然后只需要load和store它的cache块,没有任何的coherence message或者锁总线,只要它直到store之后才服务任何的coherence请求。(个人理解:变成M之后,只要它不响应coherence请求,其他的核就没法得到S或M状态的cache,因此不能读,也不能写。)
更进一步的优化为推测执行,如果cache的状态已经为S,RMW的load部分可以马上推测执行,同时cache控制器发起修改为M状态。在cache变为M状态后,再执行写部分。使用和前面类似的方式来检测预测失败,即cache是否被弹出。
Chap4 Total Store Order and the x86 Memory Model
在cache进入read-write coherence状态之前store可以进入write buffer。write buffer隐藏了store miss的延迟。
如果使用激进的预测SC实现来使得write buffer透明的话,复杂性很高,检测violation和处理mis-speculation的功耗很高。因此出现 了TSO模型。
TSO/X86的形式化定义
- 相比SC会出现Store-Load的reorder,增加了FIFO的write buffer。
- Load读到同一地址上一次Store的值。优先是按照program order在之前写入的值(从write buffer读),其次是按照memory order在之前写入的值。
- 提供了FENCE来保证顺序。
- If S(a) <p FENCE ⇒ S(a) <m FENCE /* Store → FENCE */
- If FENCE <p L(a) ⇒ FENCE <m L(a) /* FENCE → Load */
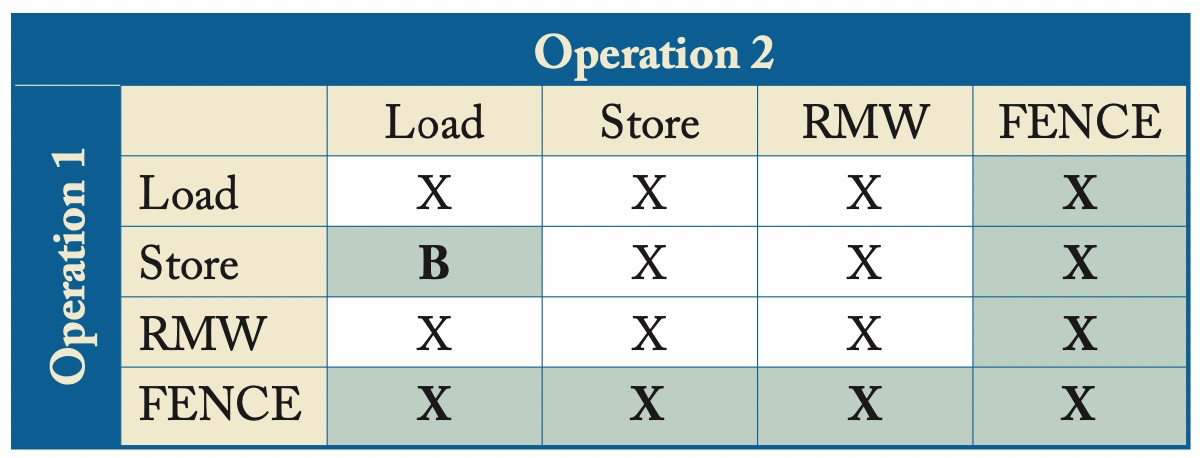
B意味着对相同地址需要bypassing。
AMD和Interl还没有正式的规范表明是TSO,但是所有的例子都符合TSO。
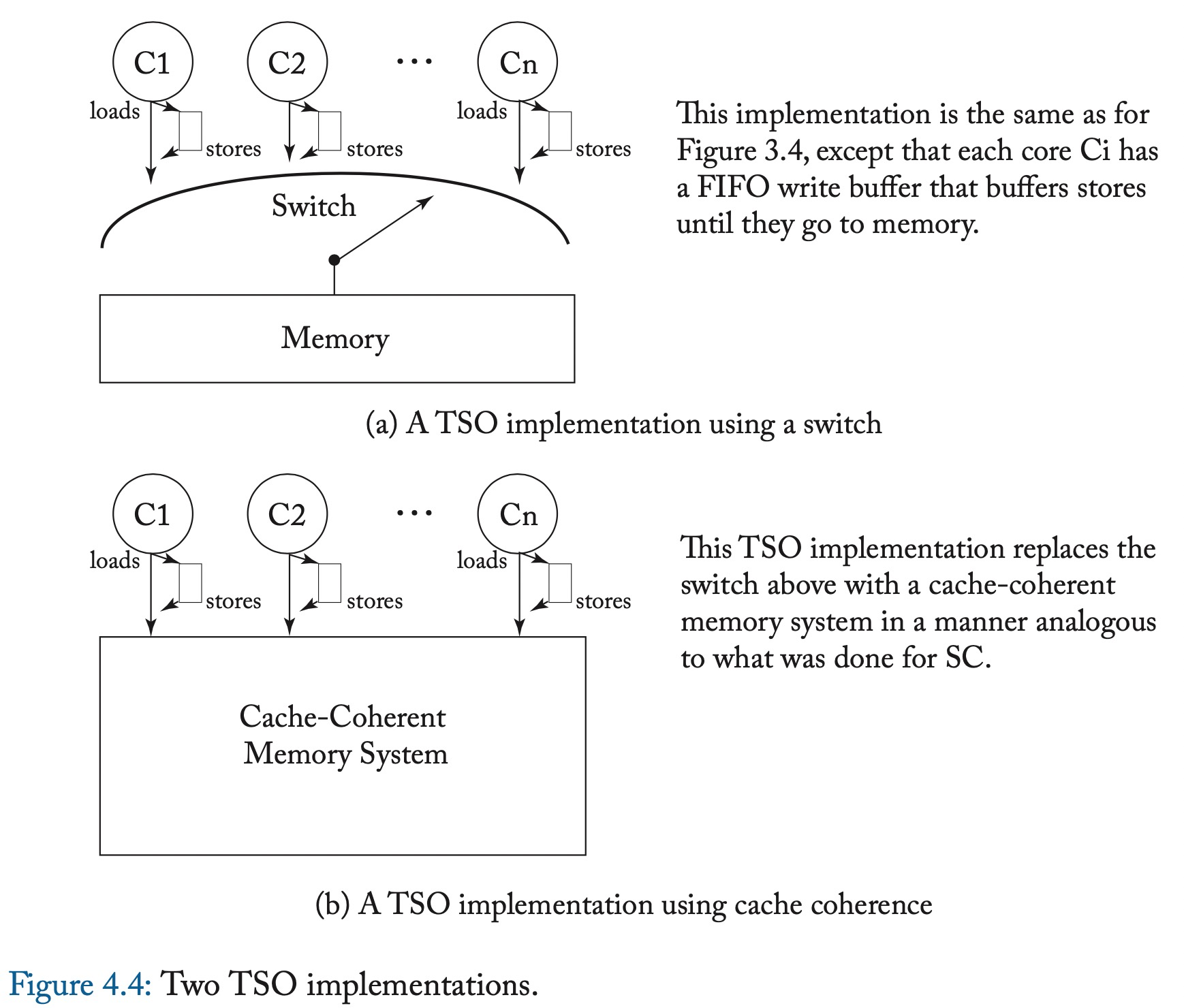
在4.4a中
- Load和Store以<p离开核。
- Load要么从write buffer bypass值,要么等待switch。
- Store进入FIFO write buffer的尾部,如果满了则stall。
- Switch选择某个核时,要么执行Load,要么执行write buffer头部的store。
4.4b中,之前讨论的SC实现依然适用。大多数TSO实现都是在SC实现上插入了write buffer。
对多线程的core,一个线程上下文不应该bypass另一个线程上下文的write buffer。可以实现为每个线程上下文的write buffer,或者共享的write buffer加上线程上下文tag。后者更加常见。
read-modify-write实现。按照TSO定义,RMW的load不能跳过之前的load。如果RMW的load跳过了之前的store,因为RMW是原子的,其store也要跳过之前的store,而TSO是不允许store跳过store的。
RMW需要之前的store有序,即需要排干write buffer。为了保证RMW的store马上在load之后,需要获得read-write的coherence权限。为了保证原子性,在load和store之间不能放弃coherence权限。
更多的优化是可行的。write-buffer在满足下面的条件时不需要排干
-
在write-buffer中的每个项在cache中有read-write权限,并在RMW提交前保持read-write权限。
-
使用MIPS R1000风格的load speculation检查。
在cache block弹出时的地址如果和load speculation的地址相同,会使得load和之前的指令都失效。在Load提交时,它一直保持在cache中,值必然相同。
逻辑上来说,RMW之前的load和store作为一个chunk整体提交。
FENCE的语义是FENCE之前的指令必须排序(应该是<m)在之后的指令之前。TSO下的FENCE不频繁,性能要求不高,在排干write buffer之后再执行load就足够了。
SC是TSO的子集。
Chap5 Relaxed Memory Consistency
5.1 动机
RMO只保持程序员需要的顺序。
如果操作不依赖许多Load和Store之间的顺序,使用relaxing order可以获得更高的性能。
优化的机会包括
- 使用非FIFO的write buffer,来获得更多的写合并。
- 不需要做复杂的core speculation,本身就允许乱序的load。
- 通过打开coherence魔盒,来获得更高的性能。允许一组核读到最新的值,而其他的核读到老的值。
eXample relaxed Consistency Model(XC)
XC不是实际的模型,假定存在global memory order,和不再使用的Alpha, SPARC RMO相同。
XC对相同地址的访问维护TSO规则。
- 相同地址的Load → Load
- 相同地址的Load → Store
- 相同地址的Store → Store
XC中的Load马上就能看到对自己核的更新(就像TSO的write buffer bypassing)。
XC的形式化定义
-
所有的核将load, store和FENCE插入<m,并遵循下面的规则
- If L(a) <p FENCE ⇒ L(a) <m FENCE /* Load → FENCE */
- If S(a) <p FENCE ⇒ S(a) <m FENCE /* Store → FENCE */
- If FENCE <p FENCE ⇒ FENCE <m FENCE /* FENCE → FENCE */
- If FENCE <p L(a) ⇒ FENCE <m L(a) /* FENCE → LOAD */
- If FENCE <p S(a) ⇒ FENCE <m S(a) /* FENCE → STORE */
-
所有的核将对相同地址的load和store插入<m,并遵循下面的规则
- If L(a) <p L’(a) ⇒ L(a) <m L’ (a) /* Load → Load to same address */
- If L(a) <p S(a) ⇒ L(a) <m S(a) /* Load → Store to same address */
- If S(a) <p S’(a) ⇒ S(a) <m S’ (a) /* Store → Store to same address */
-
Load得到对相同地址的Store的值。
Value of L(a) = Value of MAX <m {S(a) | S(a) <m L(a) or S(a) <p L(a)} /* Like TSO */
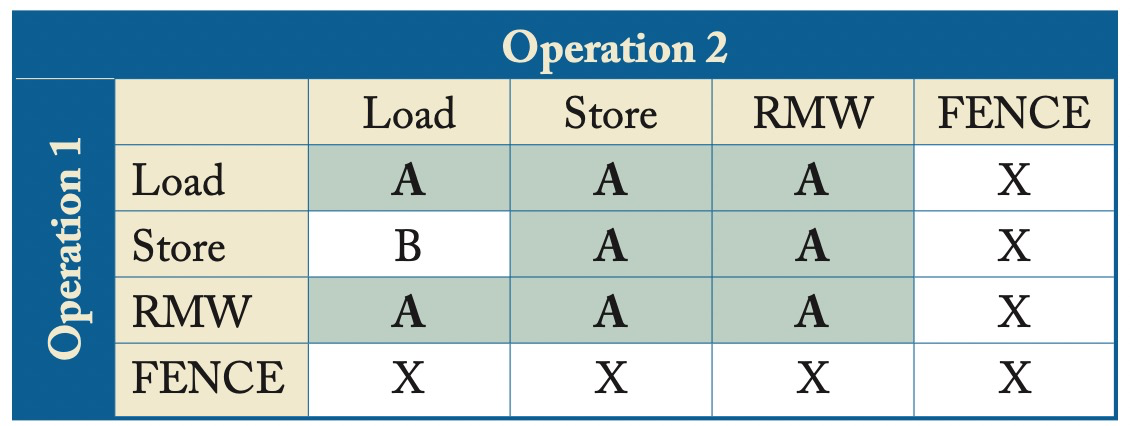
- B指对相同地址需要bypassing。
- A指对相同地址才保持顺序。
实现XC
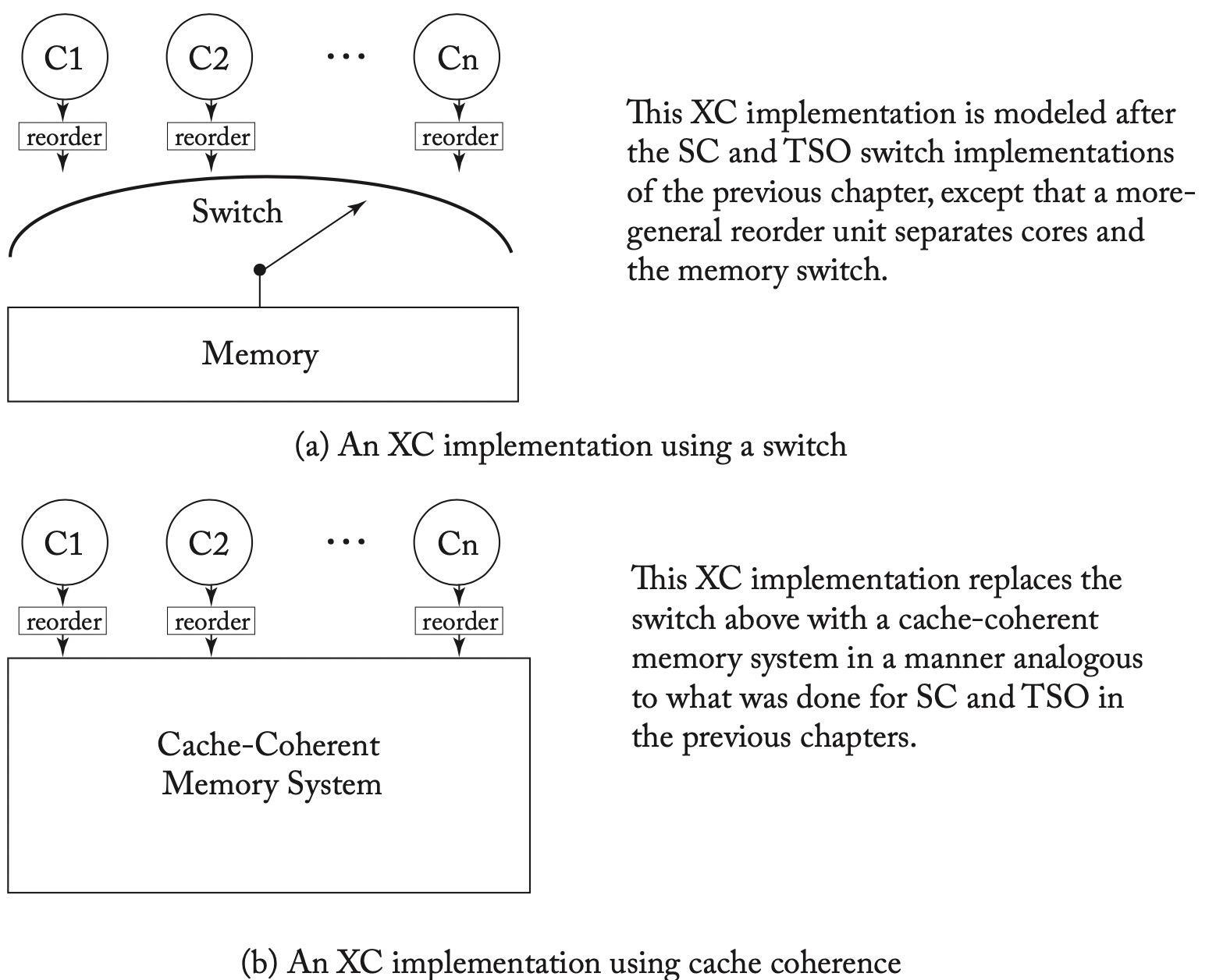
相比TSO,加上了reorder unit。
- Load, Store, FENCE以<p顺序进入reorder的尾部
- reorder unit遵循一定规则进行reorder,将操作从尾部移动到头部。FENCE到达头部后被丢弃。
- switch选取某个core时,执行reorder头部的store或者load。
作者之前预测speculative core会逐渐取代relaxed model,既能保证性能,接口又更加简单,但两方面的原因导致没有发生:厂商的冲量;低功耗的场景做不到高speculative。
XC的原子指令
XC中的RMW不需要draining write buffer,只需要获取到read-write权限,并在load部分和store部分之间不能放手。
TSO中的原子RMW就足以实现锁,而在XC中需要前后加上FENCE。

XC中的FENCE实现
- 实现SC,将FENCE作为no-op
- 将FENCE实现为drain之前的内存操作。
- 不drain,怎么做书里面没讲。
上面所有的情况中,FENCE都需要知道FENCE前的操作Xi是否结束了,在某些情况下非常tricky。
SC for DRF(data race free)
用于高阶语言做抽象,除了指定的同步操作需要保持顺序外,其他的操作允许做reorder。SC for DRF概括为下面两条
- 要么有data race,暴露了类似XC的load和store的reordering
- 要么data race free,执行看起来就像SC。
SC for DRF可以让程序员使用SC来论证程序的正确性,而不需要考虑更复杂的XC规则,而且能从XC相比SC的硬件性能提高或操作简化中受益。
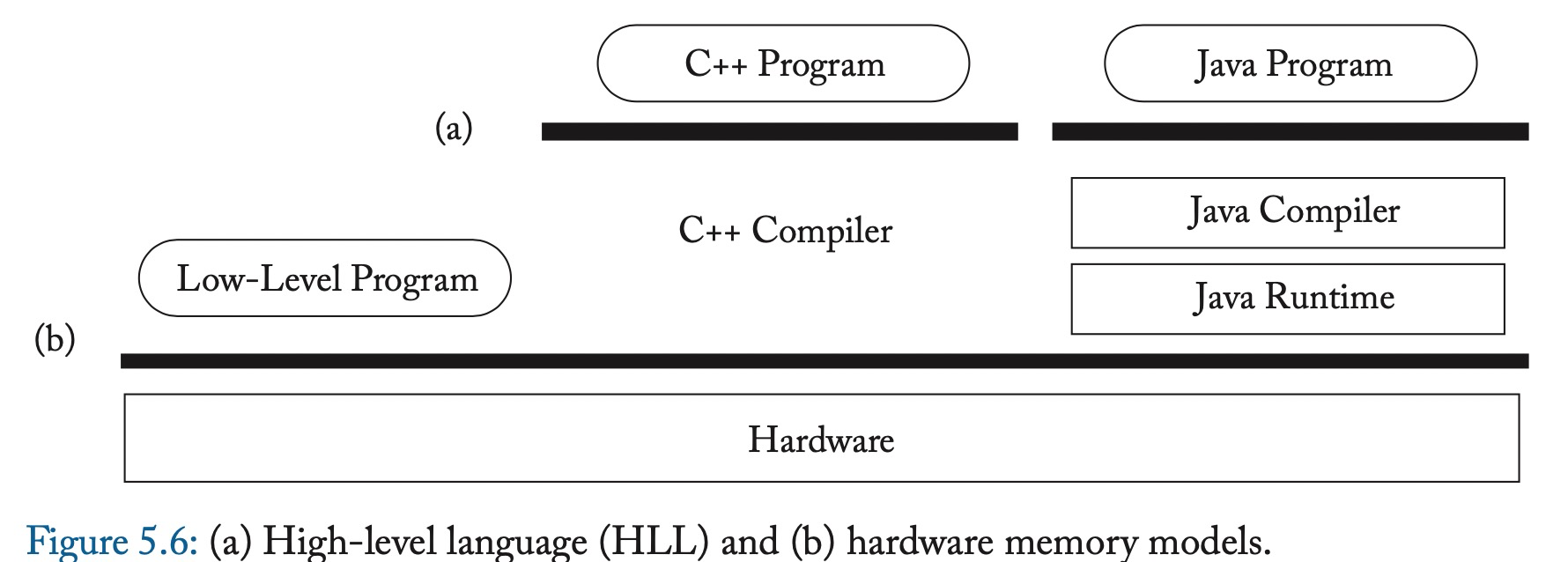
在HLL中只在必要的地方加上同步,如atomic和synchronized,在low-level program根据硬件产生合适的指令。
Java中的内存操作都是SC,C++允许更relaxed的模型。
ARMv7似乎不保证total memory order,ARMv8切换到了提供total memory order的multi-copy atomic memory order。
write atomicity, store atomicity, multi-copy atomicity。是指一个核的store在逻辑上被其他核同时可见。 write atomicity能够推导出causality,反之不然。