- Authors: Wei Cao, Yingqiang Zhang
- Created: August 21, 2022 7:46 AM
- PublishedAt: SIGMOD
- Tags: Database, serverless
- URL: https://www.cs.utah.edu/~lifeifei/papers/polardbserverless-sigmod21.pdf
- Year: 2021
Summary
通过计算、内存和存储的分离,来支持serverless按需分配资源。相当于将单机的实现原语扩展到分布式环境,使用各种方法来解决网络传输引入的问题(如时延、B树一致性)。
Strength
- serverless,进一步解耦了资源分配。
Weakness
- 比较复杂。
- 复杂场景的实用性一般,比如号称支持Auto Scaling,但是类似双十一的场景应该还支持不了。
Take Away
论文内容
概述
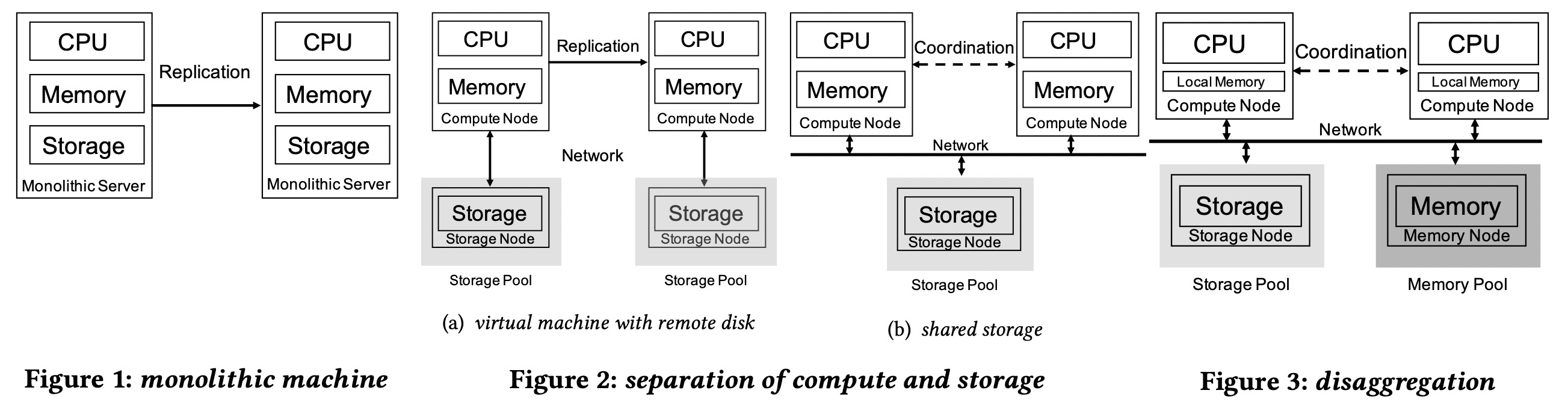
云数据库的典型架构,最右为PolarDB serverless(后面简称PS)。
单体机和存储计算分离架构的问题是,资源存在绑定关系,不能方便的按需扩展一种资源而不带来其他资源的浪费。
在PS架构中,cpu, memory和存储都可以独立提升利用率和扩展容量。而且远程内存池的数据页可以被多个数据库进程共享。增加读副本只有少量的本地内存开销。
从架构上来说,类似于将单机的各组件分布式化,所以也需要用类似cache invalidation的机制来保证事务执行的正确性。分布式化后有网络开销,为了让事务执行更快,使用RDMA高速网络连接各组件,并使用RDMA verb来做优化,例如使用RDMA CAS来优化global latch的获取。
背景
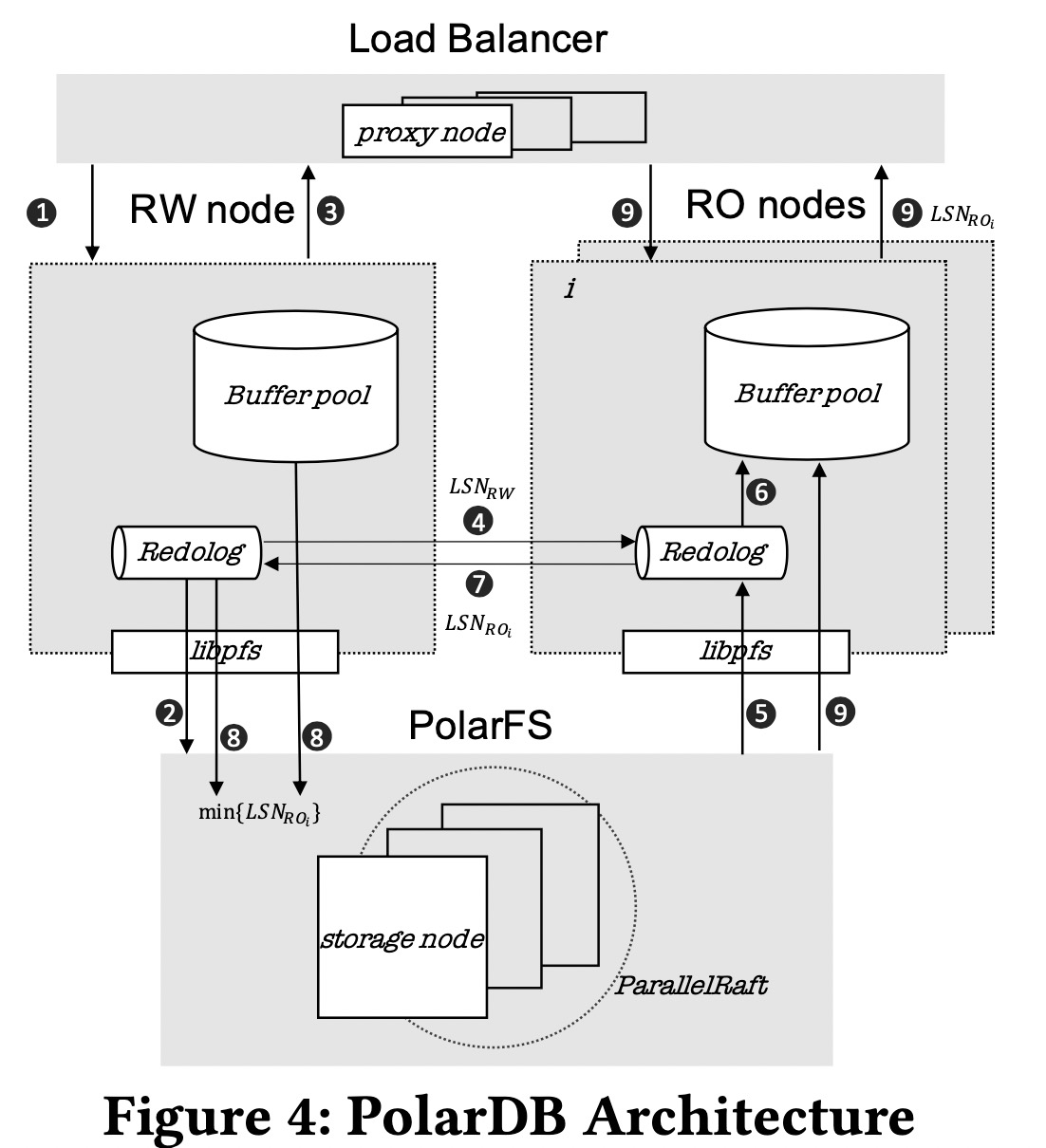
PolarDB的计算层包括一个主节点(RW)和多个读节点(RO),存储层使用PolarFS。
存储层的每个chunk有三副本,通过Parallel Raft来保证linear serializable。
RW和RO通过redo log来同步内存状态,使用LSN来协调一致性。RW将redo log刷新到PolarFS后②,事务即可以提交。RW将redo log已更新和最新的LSN_RW异步广播到所有的RO节点④。RO收到通知后,从PolarFS拉取redo log的更新,应用到buffer pool中。RO将消费的redo log LSN_RO在响应中回复给RW,然后RW可以清除已消费的redo log,将比min{LSN_RO}更老的脏页在后台刷新到PolarFS⑧。落后太多的RO节点被踢出集群,避免拖慢RW刷新脏页。
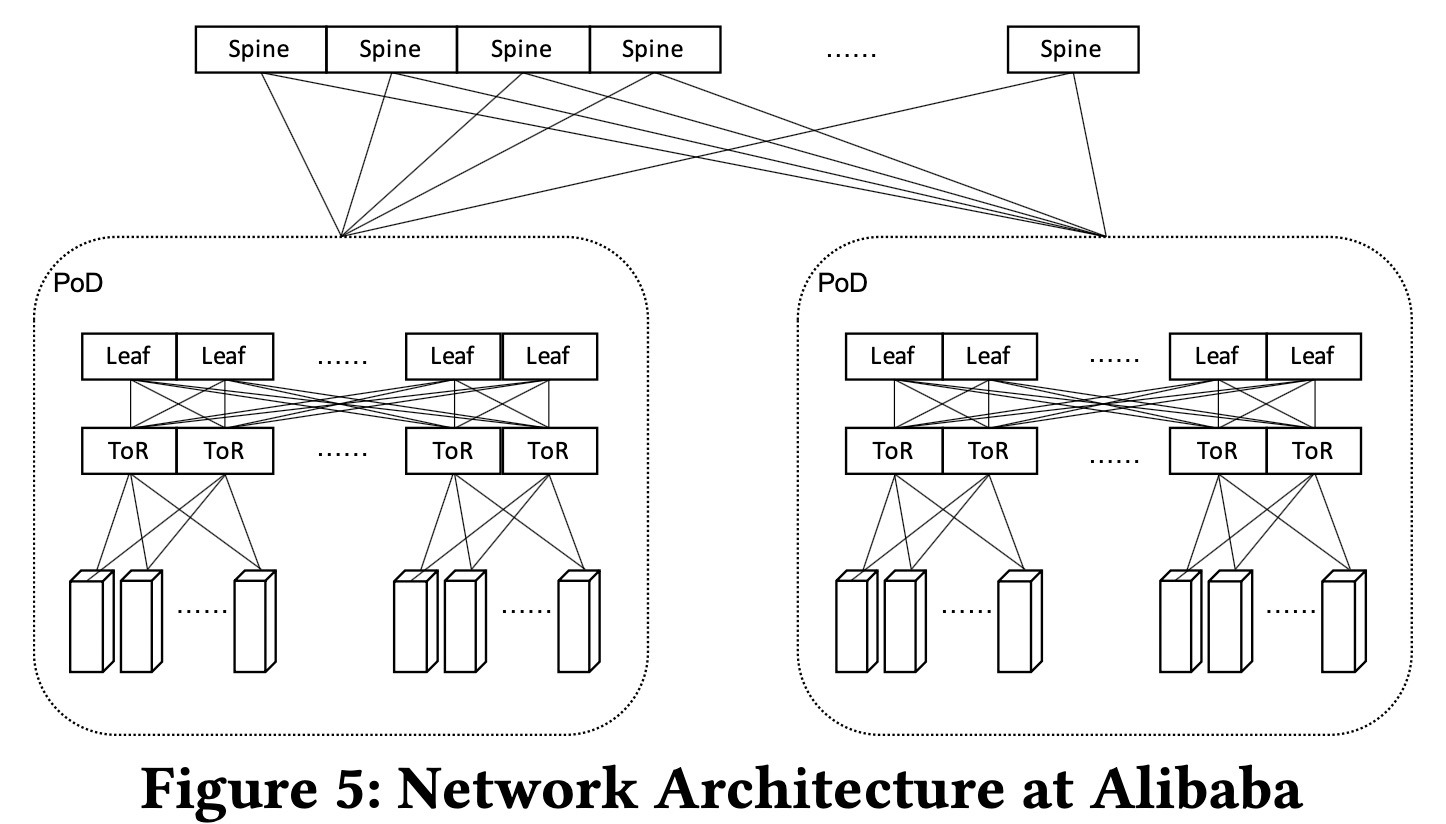
为了保证低延迟,一个数据库实例的计算、内存和存储资源分配在同一PoD下,计算和存储倾向于分配在同一ToR下面。
设计
和PolarDB架构类似,每个PolarDB serverless实例同样由多个代理节点,一个RW节点和多个RO节点构成,使用PolarFS作为底层存储池。
远程内存引入的问题及解决方案
- 访问延迟。引入分层内存系统和预取等优化。
- 内存页变为共享资源,需要跨节点互斥机制。
- 页的传输造成给网络带来负担。PS将redo log写入存储,从日志异步物化page。
Disaggregated Memory
|
|
page_invalidate用于RW来invalidate所有RO节点本地的副本。
- Page Address Table(PAT)记录每个页的位置(slab node id和物理地址)和引用计数。
- 在page_register中,home node通过查询PAT来确定页是否已存在。新创建的页加入PAT中。
- 在page_unregister中,当一个页的引用计数变为0时,从远程内存池中弹出,并删除PAT的相应项。
- Page Invalidation Bitmap(PIB)。对PAT的每个项,在PIB中有一个invalidation位。0指是最新的,1指RW已更新但没刷新到远程内存池中。每个RO节点上也有一个本地PIB。
- Page Reference Directory(PRD)。对PAT的每一项,记录引用这个页的数据库节点。PIB和PRD一起用于实现cache coherency。
- Page Latch Table(PLT)。PAT的每一项有个全局的latch,用于保证B+树的完整性。
存储支持页物化卸载,脏页也可以马上弹出而不需要先刷新。
由于网络延迟,需要本地cache。本地cache的大小采用了经验值远程内存大小/8,128GB.
如果访问的页不在远程内存中,会从PolarFS中加载,然后写入到远程内存中。并非所有从PolarFS中读到的页都需要写入到远程内存中,例如全表扫描的时候。
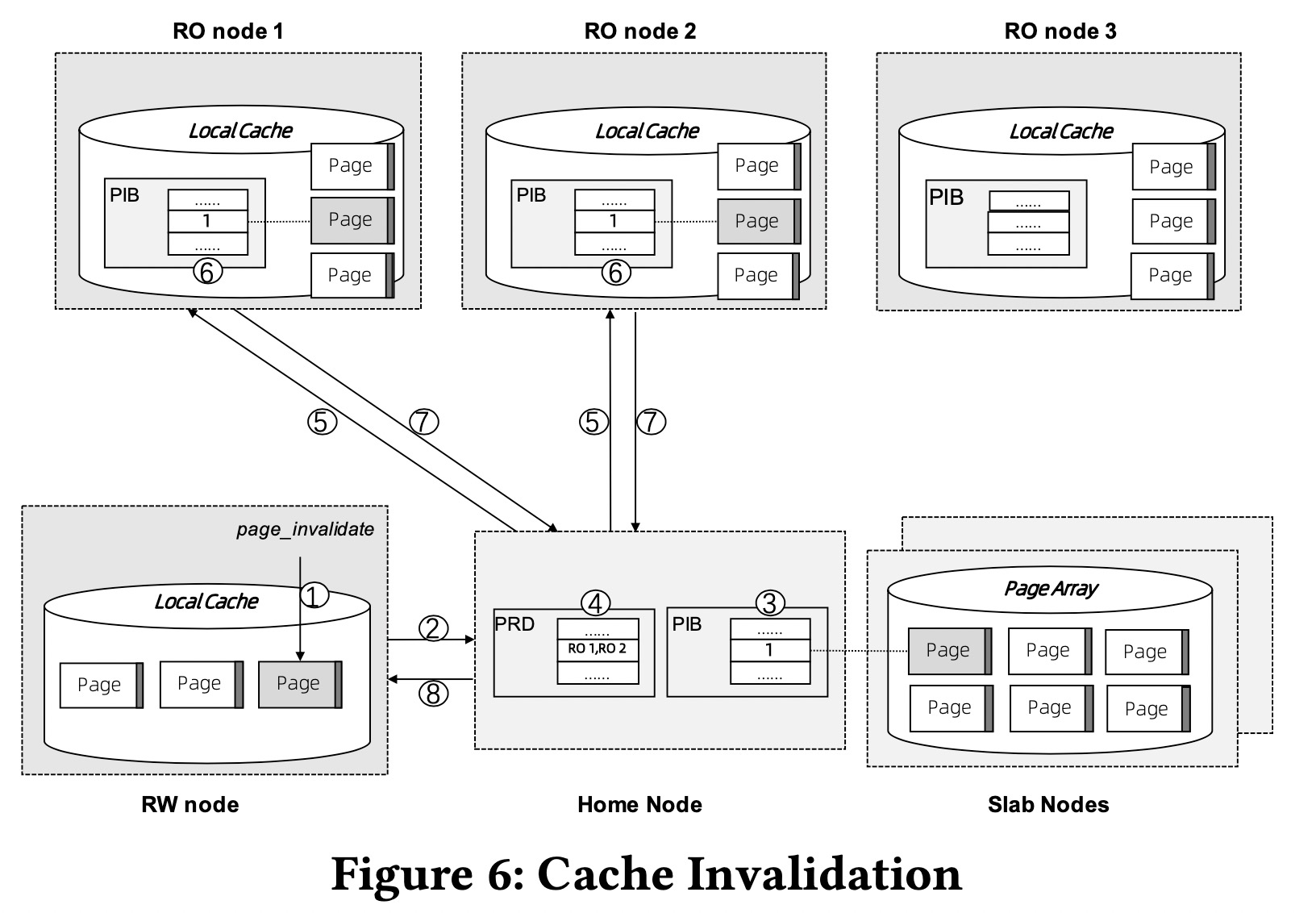
在PS中,RW可以将修改的页写回到远程内存中,然后RO马上就可见,因此不需要使用PolarDB中的redo log机制。但是,为了降低网络通信的开销,RW的修改会缓存在本地而不是马上同步到远程内存。因此需要cache invalidation机制。
RW更新本地cached的页后,调用page_invalidate①,它会设置home node上的PIB的相应位,通过查询PRD得到RO节点列表,然后设置这些RO节点上的PIB的相应位。page_invalidate是同步阻塞函数。如果异常的RO节点超时不响应,会被剔出集群以保证page_invalidate成功。
B+树结构一致性
在PS中,只有RW可以修改页,因此不需要防止多个节点导致的写冲突。但Structure Modification Operation(SMO)会同时修改多个页,可能导致RO看到不一致的结构。PS使用PL来解决这个问题。
所有SMO涉及的页需要上PL X锁直到SMO完成。因此所有RO上的读操作需要需要检查PLT看读的页是否有X锁,然后加上S锁。
对RW insert/delete操作,PS采用两步优化。假定不需要有SMO,做乐观树遍历,这时只需要本地latch。如果乐观遍历找到的叶节点页相对满或者空,有可能发生SMO,则再从root开始一次悲观遍历,同时加上X锁和X-PL锁。
为了降低PL锁的成本,PL有粘滞属性,没有读节点的请求时不需要在SMO完成后马上释放。
为了加速PL获取操作,先用RDMA CAS来尝试获取锁。如果快速路径失败,例如给已经有S锁的PL加X锁,再在home node和数据库节点间协调,调用方需要等待协调完成。
快照隔离
PS基于MVCC来实现SI(快照隔离)。
RW中维护被称为CTS的中心化的时间戳(序列号),负责给所有数据库节点分配递增的时间戳。
- 读写操作从CTS获取两次时间戳,在事务开始时获取cts_commit,在事务结束时获取cts_commit。在事务提交时将cts_commit和修改的记录一起写入。所有的记录和undo记录预留了一列来存储修改它的事务的cts_commit。事务中的读总是返回cts_commit小于事务的cts_read的最新记录。每个版本的记录还存储了修改它的事务id,因此事务认识自己的写。
- 只读事务只需要在开始时获取cts_read。
论文后面讲了如何解决都事务修改的行很多无法立即更新cts_commit的问题,通过查找RW上的CTS日志。
为了优化,使用RDMA CAS来原子的获取和递增CTS时间戳计数器。
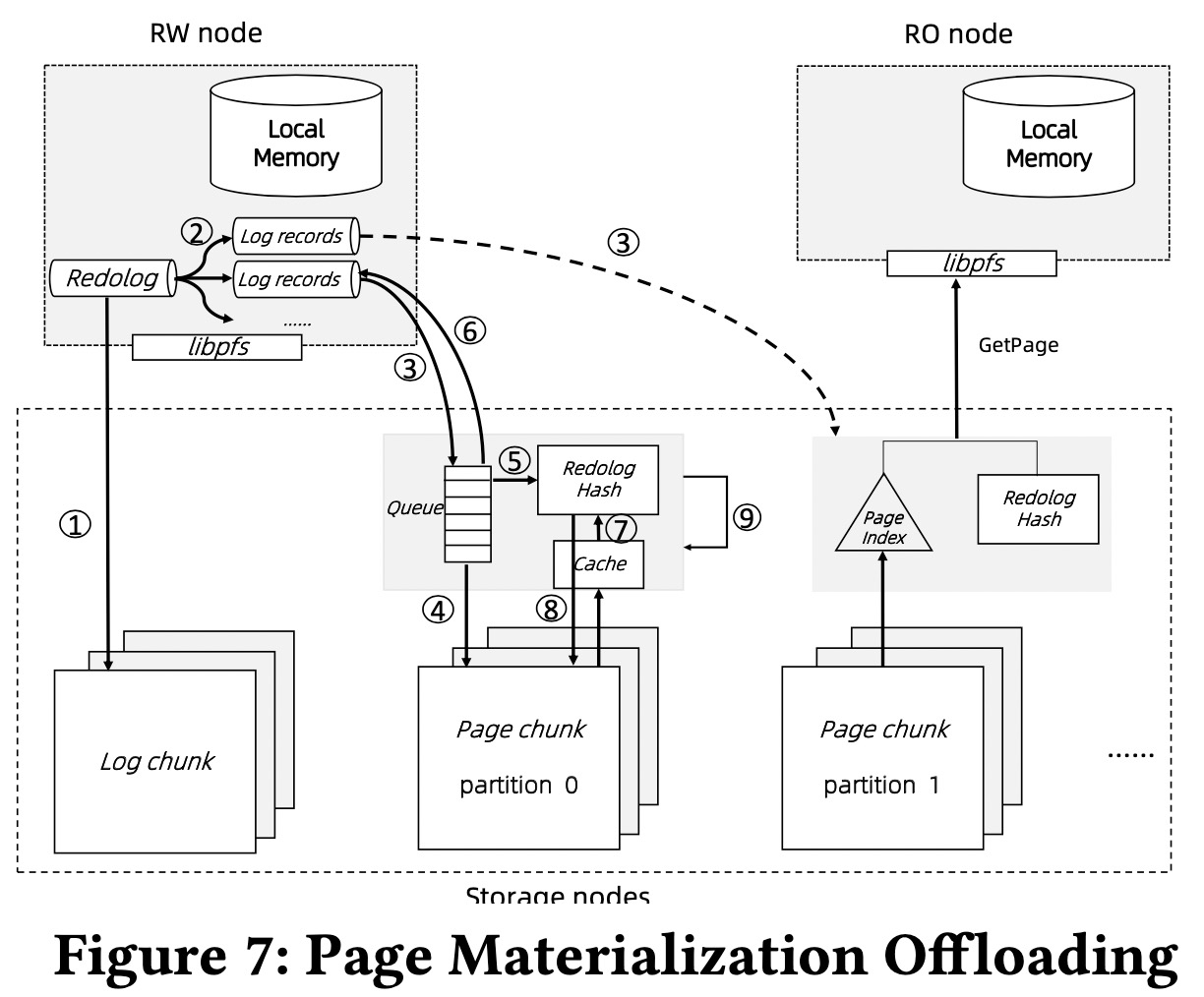
页物化卸载(Page Materialization Offloading)
传统单体DB会定期将脏页刷新到持久存储上,但在PS上这么做会导致大量网络通信。
论文扩展了PolarFS,将日志和页分开存储为log trunk和page trunk。Redo log先持久化到log trunk,然后异步发送到page trunk,log被应用以更新页。为了重用PolarFS的组件和最小化改动,日志只发送到page trunk的leader节点,再由leader节点物化页和通过ParallelRaft传播更新到其他副本。虽然增加了ApplyLog的延迟,但ApplyLog本身是异步操作不是关键路径。
Auto-Scaling
在版本升级或跨节点迁移时,proxy节点负责维护客户端连接。暂停事务执行,等待100ms,足以让老的RW节点完成大部分的进行中的语句。之后老的节点刷新脏页到共享内存并关机。同时,RW节点attach到共享内存,初始化本地内存状态。最后,proxy连接到新的RW节点,恢复会话状态,转发等待的语句来执行。老的RW节点没来得及完成的长执行的语句,将会在新的RW节点回滚后重新提交。
对于长执行的多语句事务,如批量插入,proxy对每个语句跟踪保存点,发生切换时proxy可以让新的RW node从最新的保存点继续执行。
切换时正在执行的事务需要暂停,PS使用共享内存相比传统的依赖远程存储要快。目前暂停时间为2-3秒。
性能优化
乐观锁
读节点假定没有SMO。RW维护SMO计数器,SMO_RW,SMO发生时计数器加1,SMO发生时SMO_RW的快照记录到SMO修改的每个页中(记为SMO_page)。在query的开始,获取SMO计数器的值计为SMO_query,RO从root遍历时如果发现SMO_page大于SMO_query,意味着query过程中发生了SMO,需要重试或者回退到悲观锁。
索引感知预取
Batched Key Prepare(BKP)的接口接收要预取的一组key,接口被调用时,存储引擎开启后台预取任务,从目标索引中获取需要的key,并在必要时从远程内存或存储中获取相应的数据页。
可靠性和错误恢复
数据库节点恢复
RO节点可以直接替换。
RW节点分为预期和非预期的节点替换。
**非预期的RW节点失败。**集群管理者CM通过心跳判断RW节点失败时,发起RO节点升级流程。
- CM通知内存和存储节点拒绝原RW节点之后的写请求。
- CM选一个RO节点,通知它升级了,记为RW’。
- RW’从每个PolarFS page chunk收集最新版本,LSN_chunk,其中的最小值作为检查点版本LSN_cp。
- RW’从持久化PolarFS log chunk上读取redo log记录,从LSN_cp开始读到结束位置LSN_tail,将它们分发到page chunk,等待page chunk来消费redo log和完成恢复。
- RW’扫描远程内存池,弹出invalidation位为1的页,以及页版本LSN_page大于LSN_tail的页。
- RW’释放所有原RW节点获取的PL锁。
- RW’扫描undo header来构建所有活跃事务在原RW节点失败时的状态。
- RW’在通知CM完成升级后,准备好接收新请求。
- RW’在后台回放undo log来回滚未提交的事务。
3、4两步执行ARIES的REDO阶段,并发在许多page chunk节点上执行。
大多数活跃数据仍然存在在远程内存中,可以避免传统主从复制架构的冷数据问题。
**计划内节点退位。**RW节点会做一些清理,例如同步redo log到page chunk,主动释放所有PL锁,写脏页到远程内存,最终刷新redo log到PolarFS。新的RW节点可以省去4、5、6步。另外,新节点可以推迟即位直到活跃事务数变低。
内存节点恢复
home node保存的元数据以同步的方式也保存到slave replica中。home node负责检测slave node的失败。
集群恢复
极端情况下,所有home node的副本不可用,需要做集群恢复。所有的数据库节点和内存节点从干净状态重启,所有的内存状态从存储重建。初始化之后,RW节点执行并行REDO恢复,然后扫描undo header来找到所有未完成的事务,之后开始服务,并在后台回滚未提交的事务。
集群恢复时有cold cache问题。